Clinical deployment of foundation models requires decision policies that operate under explicit error budgets, such as a cap on false-positive clinical calls. Strong average accuracy alone does not guarantee safety: errors can concentrate among patients selected for action, leading to harm and inefficient use of healthcare resources.
Here we introduce StratCP, a stratified conformal framework that turns foundation model predictions into decision-ready outputs through error-controlled selection and calibrated deferral. StratCP first selects a subset of patients for immediate clinical action while controlling the false discovery rate at a user-specified level. For the remaining patients, it returns prediction sets that achieve target coverage conditional on deferral, supporting confirmatory testing or expert review. When clinical guidelines define relationships among disease states, StratCP incorporates a utility graph to produce clinically coherent prediction sets without sacrificing coverage guarantees.
We evaluate StratCP in ophthalmology and neuro-oncology across diagnosis, biomarker prediction, and time-to-event prognosis. Across tasks, StratCP controls the false discovery rate among selected patients and provides valid, selection-conditional coverage for deferred patients. In neuro-oncology, it enables H&E-based diagnosis under a fixed error budget, reducing reliance on reflex molecular assays and lowering laboratory cost and turnaround time. StratCP establishes error-controlled decision policies for safe deployment of medical foundation models.
Overview of StratCP
Medical foundation models (FMs) achieve strong performance across imaging, pathology, and clinical prediction tasks. Several models have progressed to prospective evaluation and health system integration. Clinical deployment, however, requires more than high average accuracy. It requires decision policies that operate under explicit error budgets.
The central question is not only how accurate a model is, but when it is appropriate to act on its prediction. Clinicians must decide when to make a call, when to defer, and what follow-up to pursue. Without explicit error control, errors can concentrate among acted-upon patients. This can trigger unnecessary interventions, delay appropriate care, and waste limited diagnostic resources.
Safe clinical use of foundation models requires two guarantees:
- Action guarantee: Identify patients for whom a prediction supports immediate action under a pre-specified error budget.
- Deferral guarantee: Provide calibrated prediction sets for remaining patients, so the true disease status lies within the set at a target frequency.
The first requires error control within the acted-upon subset. The second requires coverage conditional on deferral. Marginal accuracy or marginal conformal coverage alone does not ensure these properties.
To address this gap, we introduce StratCP, a stratified conformal framework that converts foundation model outputs into decision-ready recommendations. StratCP operates as a post-processing layer and does not require retraining the underlying FM.
-
Action arm: StratCP selects patients for immediate clinical action while controlling the false discovery rate (FDR), the expected fraction of incorrect selected predictions, at a user-specified level (e.g., 5%). Selection can be defined per disease status (e.g., tumor subtype, IDH mutant, favorable early survival).
-
Deferral arm: For remaining patients, StratCP returns prediction sets that achieve selection-conditional coverage. Among deferred patients, the true disease status lies within the set at the target rate (e.g., 95%).
When diagnostic guidelines define relationships among disease states, StratCP can incorporate this structure through a utility graph. This produces clinically coherent prediction sets without sacrificing coverage guarantees.
StratCP Provides Guarantees for Safe Medical Decisions
StratCP builds on conformal prediction but extends it from marginal guarantees to action-aligned guarantees. Given a user-specified error tolerance (e.g., 5%) and labeled calibration data from the deployment setting, StratCP proceeds in two stages.
Action Arm: Select Confident Predictions Under an Explicit Error Budget
StratCP converts model outputs into candidate clinical actions, such as assigning a specific diagnosis or declaring favorable early survival (≥18 months).
For each candidate action, StratCP:
- Computes a confidence score using expert-labeled calibration data.
- Constructs conformal p-values.
- Applies false discovery rate control to select patients for whom expected prediction error remains within the pre-specified budget.
Predictions that pass this threshold enter the action arm. Clinicians can act on these decisions with an explicit FDR guarantee (e.g., ≤5% incorrect among selected patients).

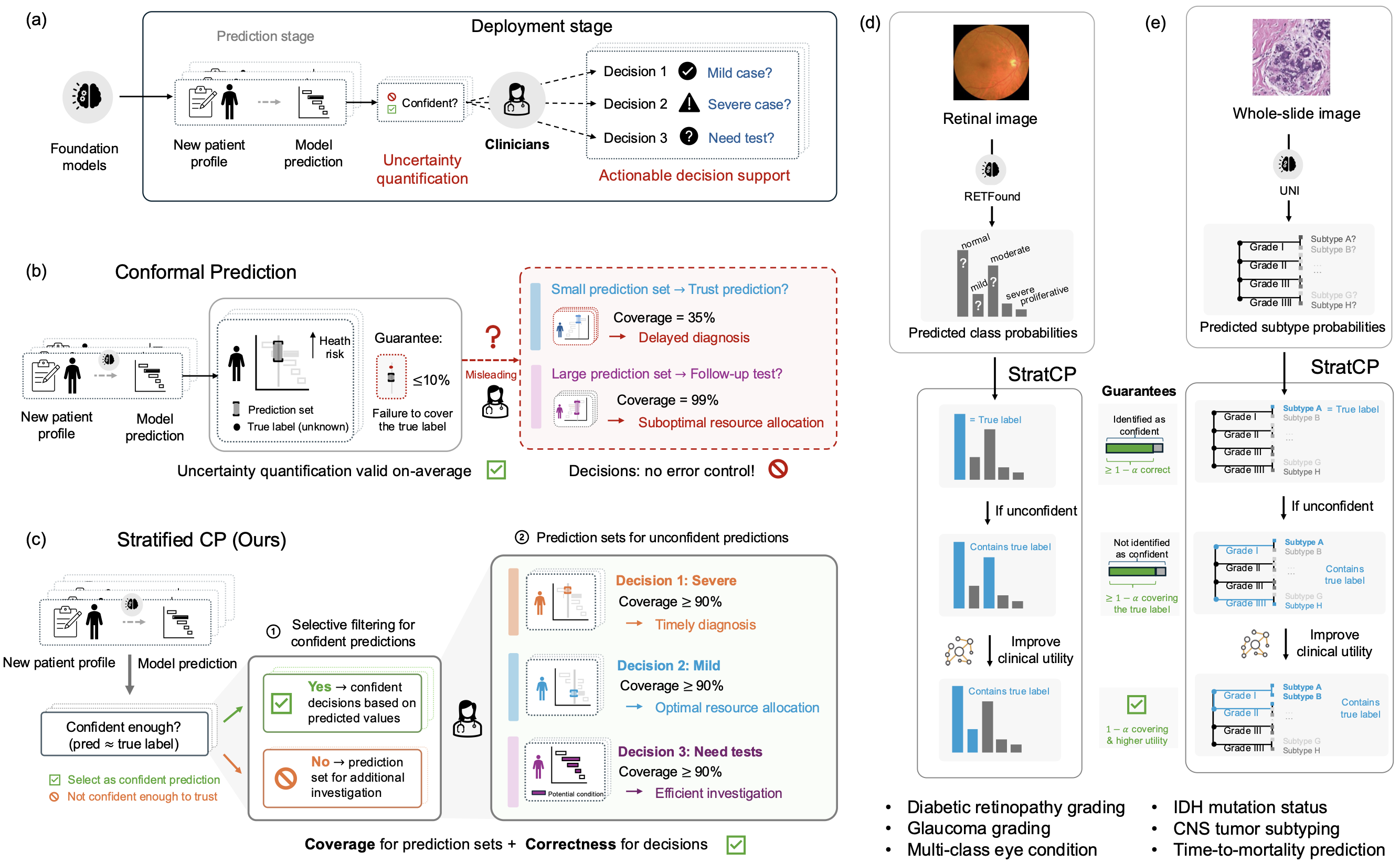
Deferral Arm: Calibrated Prediction Sets for Deferred Patients
Patients not selected in the action arm enter the deferral arm. These patients were not chosen for immediate action because their model scores did not meet the error-controlled threshold. As a result, the deferred group is not a random subset of the population. It is enriched for harder cases, those with lower top-class probability, smaller separation between leading labels, or survival scores close to the action cutoff.
This creates a distribution shift. Standard conformal prediction calibrates over the entire population, but here we need guarantees that apply specifically within the deferred subset.
StratCP addresses this by recalibrating only on calibration cases that would also have been deferred under the same action rule. Concretely, it reapplies the action-arm selection procedure to the calibration data and forms a reference group consisting of cases whose model scores fall below the selection threshold. It then constructs prediction sets using conformity scores computed within this deferral-matched reference group.
This ensures that coverage guarantees hold conditional on deferral, not just on average across all patients.
For each deferred patient, StratCP:
-
Identifies patients who would also have been deferred under the same action rule. StratCP re-applies the action-arm selection procedure to the calibration data and forms a reference group consisting only of patients whose model scores fall below the action threshold. These patients reflect situations where the model is not confident enough to support immediate action.
-
Computes conformity scores within this reference group. For each candidate label (or survival time), StratCP evaluates how well it aligns with the model’s prediction using a conformity score (e.g., cumulative probability for classification, model-based CDF values for survival). These scores quantify how typical or atypical each outcome is relative to similar deferred patients.
-
Constructs a prediction set with selection-conditional coverage. StratCP calibrates a cutoff using only the deferred reference group and includes all candidate labels whose conformity scores fall within this calibrated range. This guarantees that, among deferred patients, the true disease status lies in the prediction set at the target frequency (e.g., 95%).
This ensures that among deferred patients, the true disease status lies within the prediction set at the target rate. In time-to-event settings, StratCP returns a one-sided lower prediction bound on survival time, with coverage conditional on deferral.
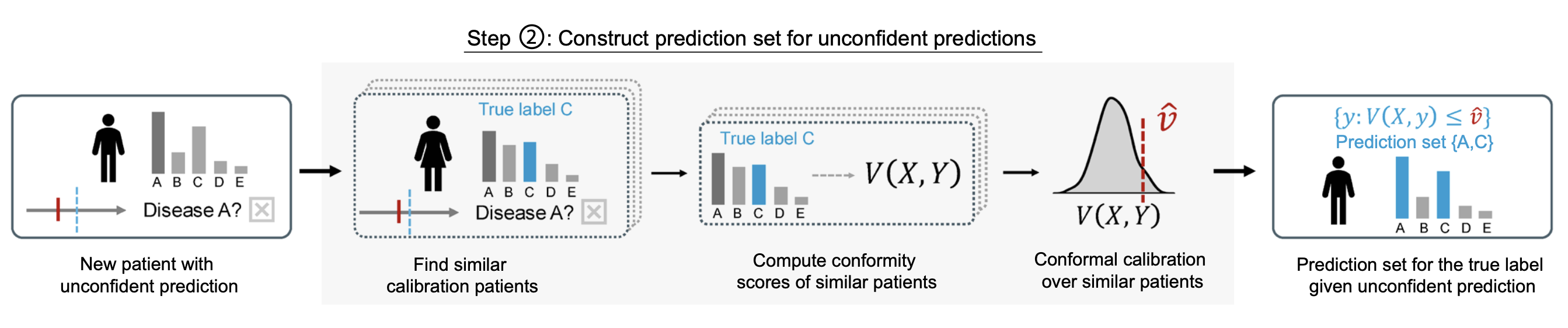
Utility Enhancement Using Diagnostic Guidelines
Standard conformal prediction constructs prediction sets using model scores alone. Labels enter the set in descending order of predicted probability. While this preserves statistical coverage, it can group clinically unrelated disease states, especially when model probabilities are close.
In clinical settings, however, labels are structured. Diabetic retinopathy follows an ordinal severity scale. CNS tumor subtypes are organized by WHO grade. Many eye conditions share downstream management pathways. Prediction sets should reflect this structure so that deferred outputs align with how clinicians reason about follow-up.
StratCP includes an optional utility module that integrates this clinical knowledge without changing the coverage guarantee.
-
Encodes guideline relationships as a utility graph. Disease statuses are treated as nodes in a graph, and edges quantify how desirable it is for two labels to appear together. Edge weights can reflect ordinal adjacency, shared tumor grade, or overlap in recommended management actions derived from guidelines.
-
Reorders candidate labels by combining predicted probability with utility. StratCP starts from the highest-probability label and iteratively adds high-probability alternatives that maximize clinical coherence with labels already selected.
-
Returns the smallest prefix that satisfies coverage. After reordering, StratCP applies standard conformal calibration and returns the minimal set needed to achieve the target coverage level.
This procedure reshapes prediction sets for clinical coherence while preserving finite-sample guarantees.
Safe Use of Medical Foundation Models With StratCP
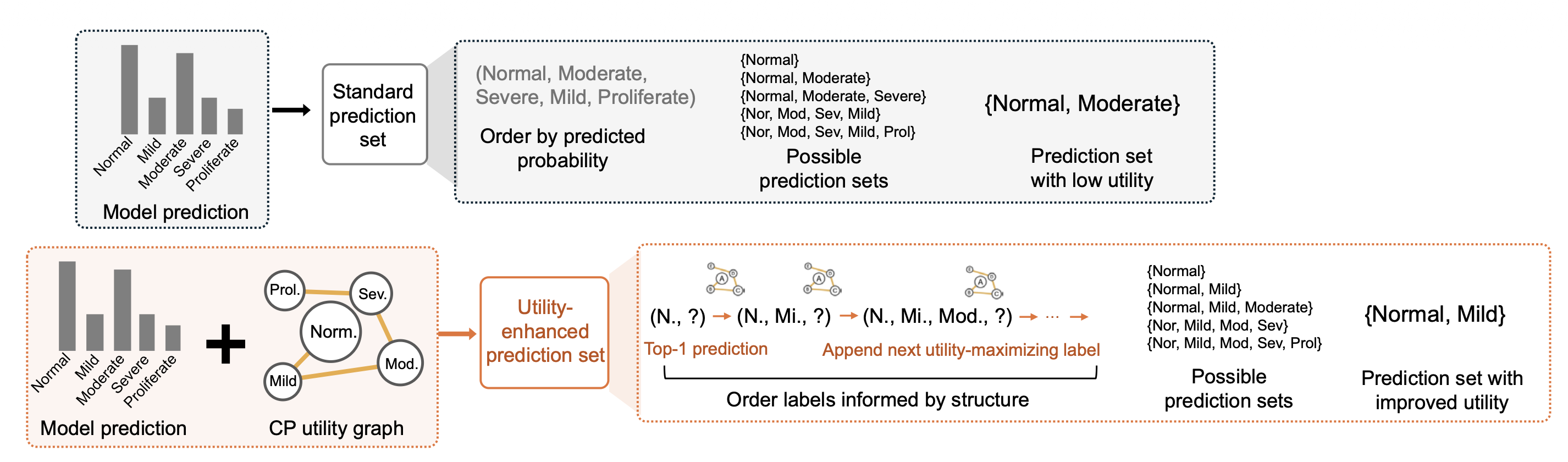
We evaluate StratCP in ophthalmology and neuro-oncology, pairing it with RETFound on retinal images and UNI on H&E whole-slide images across diagnosis, biomarker prediction, tumor subtyping, and time-to-event prognosis. StratCP controls false discoveries among selected patients in the action arm and provides selection-conditional coverage for deferred patients, so its outputs map to clinical decision points:
-
In multi-class eye-condition diagnosis (39 classes), StratCP and standard conformal prediction both achieve valid coverage, but StratCP supports action on more patients under the same 5% error budget (119.2 selected with FDR 0.048 vs. 97.5 with FDR 0.040).
-
In IDH mutation status prediction, StratCP stays within the 5% budget for IDH-mutant calls (FDR 0.046), while standard conformal prediction exceeds the budget on its selected subset (FDR 0.096).
-
In time-to-event prognosis for adult-type diffuse glioma, StratCP meets the 95% target among selected favorable early survivors (0.954), whereas a Top-1 threshold baseline falls short (0.777). StratCP also selects substantially more patients than marginal conformal selection (36.6 vs. 2.1), improving efficiency under the same error budget.
-
Utility graphs derived from diagnostic guidelines reshape deferred prediction sets without sacrificing coverage, improving clinical coherence for ordinal stages and WHO-grade relationships.
-
In adult-type diffuse glioma triage, StratCP supports H&E-only diagnosis for a subset of patients under a fixed 5% error budget, reducing reliance on reflex molecular testing and lowering turnaround time and assay cost.
Publication
Act or Defer: Error-Controlled Decision Policies for Medical Foundation Models
Ying Jin*, Intae Moon*, Marinka Zitnik
In Review 2026 [medRxiv]
@article{jin26error,
title={Act or Defer: Error-Controlled Decision Policies for Medical Foundation Models},
author={Jin, Ying and Moon, Intae and Zitnik, Marinka},
journal={In Review},
url={https://www.medrxiv.org/content/10.64898/2026.02.23.26346927},
year={2026}
}
Code and Data Availability
Pytorch implementation of StratCP is available in the GitHub repository.